ANALYZING ATTRACTIVENESS OF SPECIFIC LOCATION NAMES OF TOURIST DESTINATION FROM A CLOSED CAPTION TV CORPUS
MOCHIZUKI, HAJIME
SHIBANO, KOHJI
TOKYO UNIVERSITY OF FOREIGN STUDIES
INSTITUTE OF GLOBAL STUDIES
JAPAN.
Dr. Hajime Mochizuki
Dr. Kohji Shibano
Institute of Global Studies
Tokyo University of Foreign Studies
2-1-12 KOYAMA, Nerima
Tokyo 1760022
Japan.
Analyzing Attractiveness of Specific Location Names of Tourist Destination from a Closed Caption TV Corpus
Synopsis:
This paper describes some statistical facts about the data in our closed caption TV corpus in order to investigate the attractiveness of location names in the corpus. We will confirm whether target locations are preferred places for use in TV programs on the basis of simple word frequency, co-ocuring words, and words yielded by word2vec. In this paper, we report the result in which we analyze the attractiveness of specific location names of tourist destination from a CCTV corpus.
Analyzing Attractiveness of Specific Location Names of Tourist Destination from a Closed Caption TV Corpus
Hajime Mochizuki* and Kohji Shibano†
Abstract
This paper describes some statistical facts about the data in our CCTV corpus in order to investigate the attractiveness of location names in the corpus. We will confirm whether target locations are preferred places for use in TV programs on the basis of simple word frequency. We also investigate words co-occurring with location names in the same sentence, which can give us a clearer image of the target place than that gained by looking at simple frequency. For example, Hawaii co-occurs with many words related to local foods, shopping, sightseeing, and so on. These words are strongly related to the attractive image of Hawaii among people who watch TV programs. Similarly, in the case of Rome, many co-occurring words are related to images of world history. In addition to simple word frequency and co-occurring words, we also apply word2vec, one of the most popular natural language processing tools to detect related words, to investigate words related to a target location name as a way of clarifying their attractiveness as places for sightseeing. In this paper, we report the result in which we analyze the attractiveness of specific location names of tourist destination from a closed caption TV corpus.
Introduction
A corpus is a large, structured set of texts. Corpora have become crucial resources for researches and applications related to natural language, and a variety of studies in corpus-based computational linguistics, knowledge engineering, and language education have been reported in recent years (Flowerdew, 2011; Newman et al., 2011). We have been collecting a large-scale spoken language corpus from closed caption TV (CCTV) data transmitted through digital terrestrial broadcasting since December 2012. The size of our corpus has reached over 116,000 TV programs, over 44 million sentences and over 475 million words as of April 2015. Each TV program is classified to at least one genre according to the classifications provided in the Electric Program Guide (EPG) of which there are 12 genres: “Animation,” “Sport,” “Culture and Documentary,” “Drama,” “News,” “Variety,” “Film,” “Music,” “Hobby and Educational,” “Information and Tabloid Style,” “Welfare,” and “Other.”
One of our research interests, has involved the development of a Japanese language education system that uses examples from real situations extracted from our CCTV corpus. Because TV is a major information medium, familiar in our daily lives, we expect to be able to apply the corpus to language education, offering realistic examples of conversation conducted through e-learning systems (Mochizuki and Shibano, 2014; Mochiuzki and Shibano, 2015a).
* Institute of Global Studies, Tokyo University of Foreign Studies
† Research Institute for Languages and Cultures of Asia and Africa, Tokyo University of Foreign Studies
In addition to using our corpus as learning materials, we are positioned to employ the corpus in a wide variety of research areas as a language and cultural resource. In general, TV is a medium for information on culture, sports, and current events. Thus, we expect that various topics related to events receiving recent attention and to specific locations and subjects can be extracted from the corpus, such that it will act as a rich chronicle of our Japanese culture (Mochizuki and Shibano, 2015b).
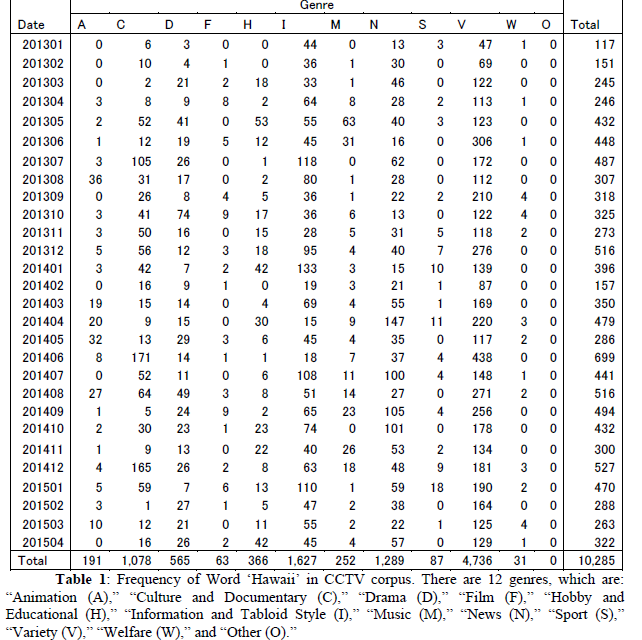
Among these various topics, this paper focuses on topics related to specific locations in foreign places that are treated in Japanese TV programs as attractive places for the audience to consider visiting for sightseeing purposes. For example, Hawaii is a famous and popular locations for sightseeing in Japan, and is represented as such in Japanese TV programs. The word Hawaii occurs 10,285 times in our CCTV corpus over 28 months. Table 1 shows the frequency of word Hawaii in our CCTV corpus from January 2013 to April 2015 across 12 genres.
As shown in Table 1, the word Hawaii frequently occurs in four genres “Culture /Documentary (C),” “Information/ Tabloid Style (I),” “News (N),” and “Variety (V)” respectively 1078, 1627, 1289 and 4736 times. Because these four genres will be more related to cultural, informative, and entertaining topics than other genres, we presume that Hawaii will yield attractive and exciting emotions. Therefore, we focus on these four genres.
We believe that location names in the closed caption TV corpus can be analyzed to determine their attractiveness as sightseeing places. In order to select location names, we set three conditions: (1) they are popular destinations for Japanese overseas travelers, (2) they are served by international flights, and (3) their frequency in the CCTV corpus is sufficiently
high to collect adequate data for analysis.
In this paper, we report some statistical facts regarding our CCTV corpus that encouraged us to utilize the corpus to analyze the attractiveness of specific location names for sightseeing. In addition to a list of single words by frequency, we investigate words co-occurring in the same sentence as location names; we also apply word2vec (Mikolov et al., 2013), one of the most popular natural language processing tools, to detect words related to a target location name.
Simple frequencies of location names in the CCTV corpus
In order to select word i, consisting of a city, region or country name, we set the following three conditions.
1. Word i is a very popular destination for Japanese overseas travelers. Under this condition, we selected location names from countries that were the destination of more than 300,000 Japanese travelers in 2011 with reference to statistics for Japanese overseas travelers provided by the Japan Association of Travel Agents (JATA).
2. Word i is listed in a destination list of international flights by Japanese airline companies.
3. The frequency of word i is more than once per 100,000 words in genre V in our CCTV corpus. We prefer to use genre V as opposed to the other three genres because most travel TV programs are classified in genre V by TV stations.
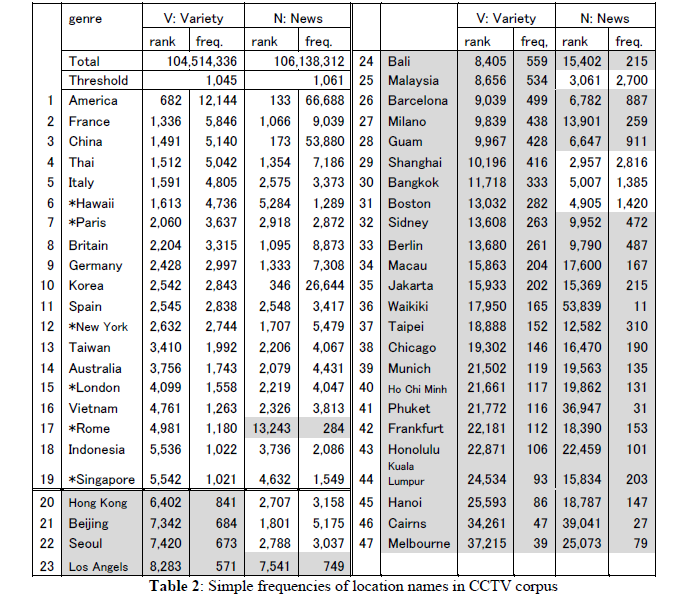
Table 2 shows the result of calculation of simple frequencies of 47 candidate location names in genres V and N. In all, 19 candidates satisfied the above three conditions. As shown in Table 2, frequencies of 18 among 19 candidate location names, all except for Rome are over the threshold in genre N as well as V. These result shows that words that frequently occur in Japanese variety programs tend also to frequently appear in Japanese news programs. Among the 19 location names, 13 are country names; the remaining six are cities or regions (Singapore is placed in this category, although it is also an independent country). In this paper, we take up these six subnational location names: Hawaii, Paris, Rome, New York, London, and Singapore. Figure 1, 2, 3, 4, 5, and 6 show monthly frequencies of these six words across genres C, I, N, and V.
These six location names can be classified into two groups according to their frequency in genre N. The first group includes Hawaii, Paris, and Rome, and the latter, New York, London, and Singapore. The members of group two tend to appear in genre N more frequently than in the other genres, in contrast to the members of the first group, which appear most often in genre V. Hawaii, Paris, and Rome, in group one, are major sightseeing destinations, while New York, London, and Singapore, in group two, are also major cities for the world economy. Therefore, we expect that the latter locations will be treated in economic news frequently, accounting for their frequency in N.
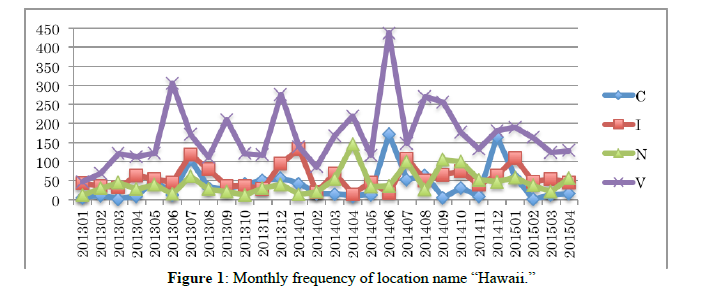
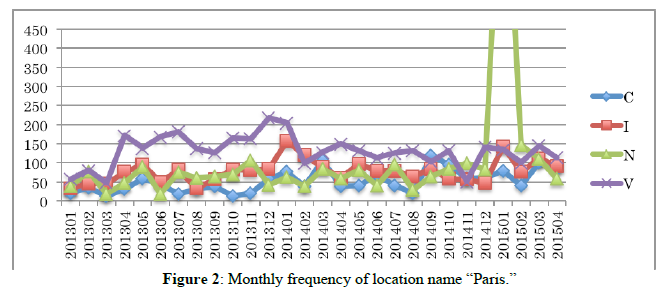
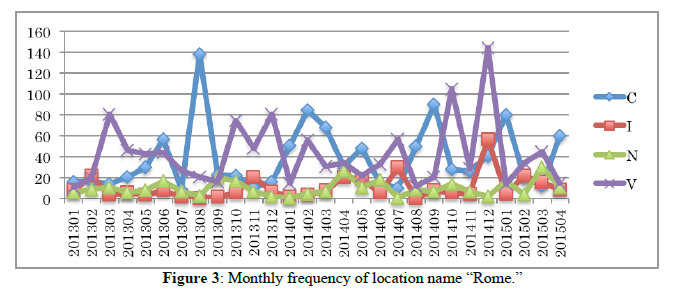
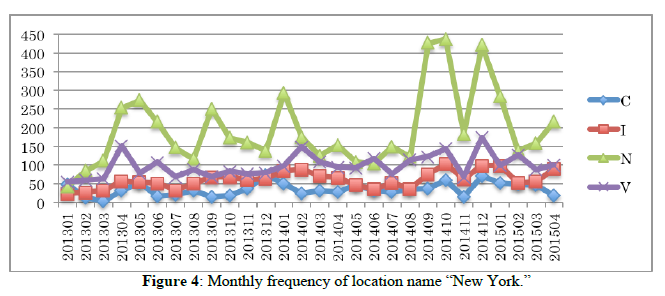

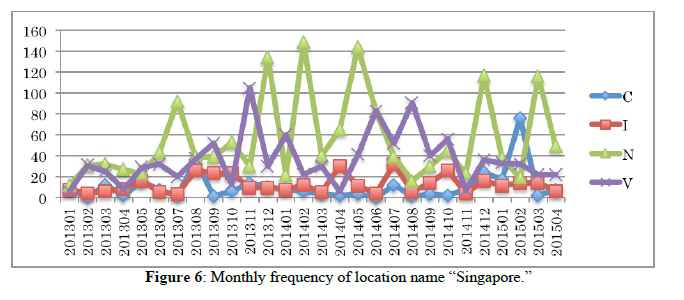
Proportion of occurrences is not consistent from genre to genre. As seen in Figure 1, the occurrence of Hawaii in genre V (a purple line) tends to increase every December and every June, while in genre I (an orange line) it tends to increase every January and every July. These statistic results seem intuitively reasonable, since in general Japanese people take relatively short vacations at the same time each year the vast majority, a week around the end/beginning of the year, a week between the end of April and the beginning of May (called “Golden week”), and a summer vacation one or two weeks in August. Therefore, we would programs related to attractive destinations such as Hawaii to be more common in these vacation periods. Indeed, similar tendencies for Paris, Rome, and Singapore are shown for genre V in Figures 2, 3, and 6. Many Japanese people will travel abroad at the same time during these vacation seasons like an annual event. Therefore, attractive oversea locations are featured by many TV programs precedent for Japanese vacation seasons. It can be said that at least Hawaii, Paris, Rome, and Singapore are the most preferred places to be introduced and featured in TV programs.
Words co-occurring with location names in the CCTV corpus
In this section, we provide some statistical facts regarding our corpus, in addition to a simple list of words according to frequency. In particular, we investigate words that co-occur with location names in the same sentence.
Table 3 shows an example list of words co-occurring with the location name, Hawaii in the same sentence. The words in Table 3 can be classified into five groups: Words in the first group are generally found in sentences like “We go to Hawaii for sightseeing” or “We will go traveling to Hawaii.” The second group of sentences relates to shopping or dining events. The third group consists of words related to weddings in Hawaii, considered a prestigious wedding destination among young Japanese women. These three groups of words will strongly relate to the attractive image of Hawaii among people who watch TV programs. The fourth and fifth groups, on the other hand, are different from the first three groups; in that the words in the fourth and fifth groups appear with the greatest frequency in genre N. For example, volcano and tsunami in group four relate not to social or cultural events, but to natural disasters. These words in genre N remind us about terrible natural disasters that happened in past few years.
Table 4 shows words co-occurring with Rome, which show a different tendency from those co-occurring with Hawaii. Because the city of Rome has an extensive ancient history, many of its co-occurring words tend to appear in genre C, whose theme is related to cultures (including history).
Both Hawaii and Rome are very popular and attractive destinations for Japanese people, and both occur in the CCTV corpus frequently.
It is difficult to classify words co-occurring with Paris. This wide variety of co-occurring words may imply that Paris is seen as having diverse cultural and other attractions, which Japanese TV programs wish to convey to their watchers.
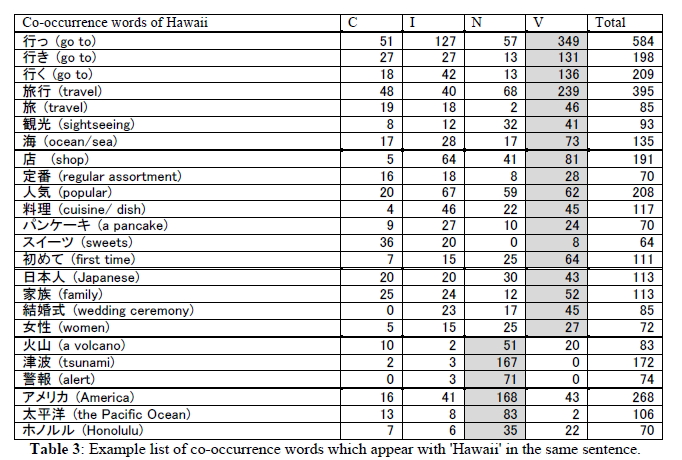


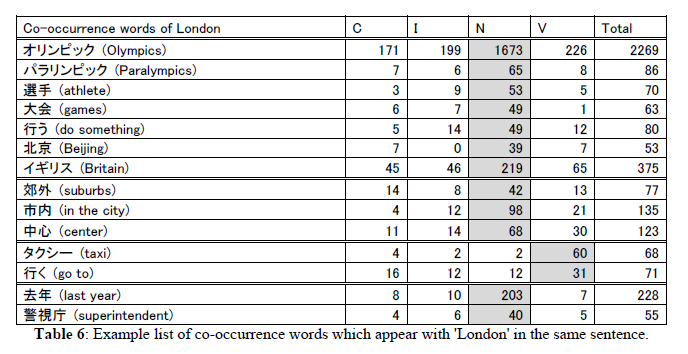
Table 6 shows a list of co-occurring words with London. In contrast to Hawaii, the word London has frequently co-occurs with words in the news genre, N: many of these are words related to the 2012 London Olympic Games and Paralympics, such as Olympics, Paralympics, athlete, and games. In this investigation, we find only two kinds of words frequently co-occurring with London that are in genre V: go to and taxi. This seems to indicate that the attractiveness of London as a sightseeing destination is lower than that of Hawaii, at least as represented in our CCTV corpus.
Closest words to the location names in the CCTV corpus
Here we apply word2vec (Mikolov et al., 2013), one of the most popular natural language processing tools, to find the closest words for user-given words in the corpus.

Table 7 shows the closest words to six location names, Hawaii, Paris, Rome, New York, London, and Singapore, respectively. Numeric values in brackets mean cosine distance as calculated by the “distance” tool of word2vec.
As shown in Table 7, a large portion of the closest words are world-famous location names, across both genres N and V. However, each location has a different group of closest words, indicating the complexity and distinctiveness of their images. For example, the closest words to Hawaii include the names of individual Hawaiian islands and other resort locations, such are Las Vegas, Macau, Okinawa and Phuket. The closest words to Rome include many places with a similarly ancient history, such as Egypt, Greece, Acropolis, and Milano. In genre N, we can observe words related to recent news about the target locations. For example, most words related to London are associated with the Olympics and Paralympics, at least in our CCTV corpus. Singapore is related to Lee Kuan Yew, the first prime minister of Singapore, in genre N. At least from the results of this paper, it seems that word2vec is not suitable for analyzing the attractiveness of a target location, but does work for finding other locations that have similar images.
Conclusions
In this paper, we have reported some statistical facts regarding our CCTV corpus in order to investigate the attractiveness of location names in the corpus. We counted simple frequencies of 47 location names, and selected six of these that were not country names: Hawaii, Paris, Rome, New York, London, and Singapore. From simple word frequency results, we could confirm that at least Hawaii, Paris, Rome, and Singapore are viewed as preferred places for feature status on TV programs.
In addition, we investigated words co-occurring with these six location names in the same sentence. Co-occurring words were able to give a clearer image of the target places as compared with simple frequency. For example, in the case of Hawaii, there were many co-occurring words about foods, shopping, sightseeing and so on. That is, they were all strongly related to the attractive image of Hawaii among people who watch Japanese TV programs. Similarly, in the case of Rome, many co-occurring words were related to images of world history.
Finally, we also applied word2vec, one of the most popular natural language processing tools, to detect related words for a given target location name. At least in our results, it seemed that word2vec was not suitable for analyzing the attractiveness of a target location, but did work finding other locations with similar images.
Acknowledgments
This research was supported by JSPS KAKENHI Grant Numbers 26240051 and15H02794.
References
Mochizuki, H. & Shibano, K. (2014). Building Very Large Corpus Containing Useful Rich Materials for Language Learning from Closed Caption TV. World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education, Volume 2014, No. 1, (pp. 1381-1389). Association for the Advancement of Computing in Education (AACE), New Orleans.
Mochizuki, H. & Shibano, K. (2015a). Development of a Closed Caption TV Corpus Retrieval System to Seek Video Scenes Containing Useful Expressions for Language Learning. The EdMedia World Conference on Educational Media and Technology, (to appear, nine pages). Association for the Advancement of Computing in Education (AACE), Montreal, Canada.
Mochizuki, H. & Shibano, K. (2015b). Detecting Topics Popular in the Recent Past from a Closed Caption TV Corpus as a Categorized Chronicle data, the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (KMIS) 2015, to appear, Lisbon, Portugal.
Flowerdew, L. (2011). Corpora and Language Education. Palgrave Macmillan.
Newman, J., Baayen, H. & Rice, S. (2011). Corpus-based Studies in Language Use, Language Learning, and Language Documentation. (Language and Computers Studies in Practical Linguistics), Rodopi.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at International Conference on Learning Representation (ICLR) 2013, Scottsdale, AZ.